2025. 1. 11. 14:22ㆍProgramming/python

Python 기초 웹크롤링 가이드
웹크롤링은 데이터를 수집하거나 분석하는 데 매우 유용한 기술입니다. Python은 다양한 라이브러리와 간단한 문법 덕분에 초보자들도 쉽게 웹크롤링을 배울 수 있는 언어로 알려져 있습니다. 이번 포스팅에서는 Python을 활용한 기초 웹크롤링 방법을 다뤄보겠습니다.
1. 웹크롤링이란?
웹크롤링(Web Crawling)은 웹페이지의 데이터를 자동으로 가져와 분석하거나 저장하는 기술입니다. 흔히 스크래핑(Web Scraping)이라고도 부르며, 검색 엔진, 데이터 분석, 가격 비교 서비스 등에서 활용됩니다.
주의사항: 웹크롤링은 반드시 타인의 권리를 침해하지 않는 범위 내에서 사용해야 합니다. 해당 웹사이트의 robots.txt 파일을 확인하거나 이용 약관을 준수해야 합니다.
2. Python 웹크롤링에 필요한 라이브러리
Python에서 웹크롤링을 위해 주로 사용하는 라이브러리는 다음과 같습니다:
- requests: 웹페이지 데이터를 요청하여 가져옵니다.
- BeautifulSoup: HTML 데이터를 파싱하고 원하는 정보를 추출합니다.
- pandas: 데이터를 테이블 형식으로 저장하고 분석합니다.
설치 명령어
아래 명령어를 사용하여 필요한 라이브러리를 설치할 수 있습니다:
pip install requests beautifulsoup4 pandas3. 웹크롤링 기초 코드 작성
아래는 Python으로 간단한 웹크롤링을 수행하는 코드 예제입니다. 이 코드는 특정 웹페이지의 제목(title)을 가져옵니다.
import requests
from bs4 import BeautifulSoup
# 1. 웹페이지 요청
url = "https://example.com"
response = requests.get(url)
# 2. 응답 확인
if response.status_code == 200:
html = response.text
# 3. HTML 파싱
soup = BeautifulSoup(html, 'html.parser')
# 4. 제목 추출
title = soup.title.text
print(f"페이지 제목: {title}")
else:
print(f"요청 실패: {response.status_code}")4. 주요 요소 추출하기
웹페이지에서 특정 데이터를 추출하려면 HTML 구조를 이해하고 적절한 선택자를 사용해야 합니다.
HTML 구조 예시
<div class="article">
<h2>Python 웹크롤링</h2>
<p>웹크롤링은 데이터를 수집하는 기술입니다.</p>
</div>데이터 추출 코드
# 원하는 요소 찾기
article = soup.find('div', class_='article')
heading = article.find('h2').text
content = article.find('p').text
print(f"제목: {heading}")
print(f"내용: {content}")5. 데이터 저장하기
추출한 데이터를 CSV 파일로 저장하면 활용도가 높아집니다. 아래는 pandas를 활용한 저장 예제입니다:
import pandas as pd
# 데이터 준비
data = [
{"제목": heading, "내용": content}
]
# 데이터프레임 생성 및 저장
df = pd.DataFrame(data)
df.to_csv('data.csv', index=False, encoding='utf-8-sig')
print("데이터가 저장되었습니다.")6. Google Colab으로 테스트하기
Google Colab은 별도의 Python 환경 설정 없이도 쉽게 웹크롤링 코드를 실행할 수 있는 온라인 도구입니다. 다음은 Google Colab에서 테스트할 수 있는 예제입니다:
6.1 Colab 노트북 시작하기
- Google Colab에 접속합니다.
- 새 노트북을 생성합니다.
6.2 코드 실행
아래 코드를 Colab 셀에 복사하여 실행하세요:
# 라이브러리 설치
!pip install requests beautifulsoup4 pandas
# 라이브러리 임포트
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 1. 웹페이지 요청
url = "https://example.com"
# "https://example.com" 해당 url을 원하는 크롤링할 사이트를 적용
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 2. 데이터 추출
title = soup.title.text
print(f"페이지 제목: {title}")
# 3. 데이터 저장
data = [{"제목": title}]
df = pd.DataFrame(data)
df.to_csv('data.csv', index=False, encoding='utf-8-sig')
print("데이터가 저장되었습니다.")
else:
print(f"요청 실패: {response.status_code}")6.3 결과 확인
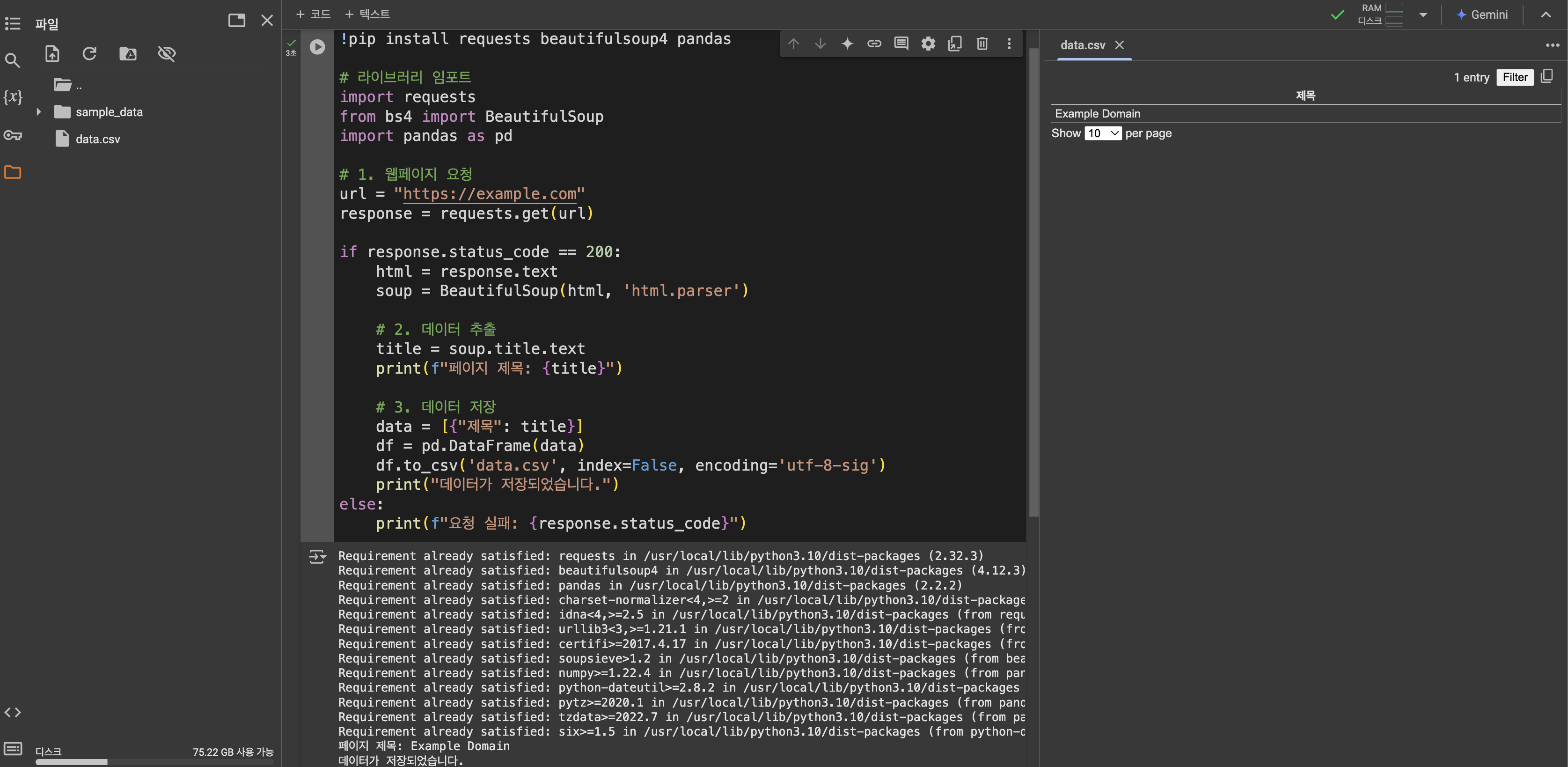
- 출력 창에 "페이지 제목"이 표시됩니다.
- 생성된 data.csv 파일을 Colab 왼쪽 탐색 메뉴에서 다운로드할 수 있습니다.
결과 이미지
7. SEO 최적화된 웹크롤링 팁
- 정확한 키워드 사용: 크롤링 대상 웹페이지의 HTML 구조를 분석해 필요한 데이터를 정확히 추출하세요.
- 시간 간격 조정: 서버 부하를 피하기 위해 요청 간 시간을 조정하세요. 예를 들어, time.sleep(1)를 추가해 1초 간격으로 요청을 보낼 수 있습니다.
- API 활용: 가능하다면 공개 API를 활용해 데이터를 수집하세요. API는 데이터 접근이 더 효율적이며 안정적입니다.
8. 마무리
이 글에서는 Python으로 웹크롤링을 시작하는 데 필요한 기초적인 방법을 설명했습니다. Google Colab에서 쉽게 테스트할 수 있는 샘플 코드도 추가했으니, 직접 실행하며 실습해 보세요. 앞으로 다양한 웹페이지를 크롤링하고 데이터를 활용해 보세요.
추가 학습 자료:
구독과 좋와요 부탁드립니다!!
'Programming > python' 카테고리의 다른 글
| 로또 당첨 번호 데이터 추출 하여 데이터화하기(python, mysql) (8) | 2025.02.07 |
|---|---|
| 역대 로또 당첨 번호 데이터 추출 ver.python (8) | 2024.12.31 |
| 파이썬 랜덤 번호 추출하기(Python Tutorial: Building a Random Number Generator) (3) | 2024.11.12 |
| Pytrhon 설치없이 사용하기 - Colaboratory(코랩) (0) | 2023.07.02 |
| python 간단한 ai 코드 (0) | 2023.07.01 |